Fujitsu develops video analytics AI agent to support safe, secure, and efficient frontline workplaces
![]()
KAWASAKI, Japan, Dec 12, 2024 - (JCN Newswire) -Fujitsu today announced the development of a video analytics AI agent for frontline workplaces. The AI agent uses spatial video and image data from workplace camera footage, as well as written information, to draft reports and make recommendations for workplace improvements. The AI agent will be positioned as a core technology of Fujitsu’s AI service "Fujitsu Kozuchi". Fujitsu will provide a trial environment for the AI agent in fiscal year 2024 and commence in-house implementation from January 2025.
The AI agent is based on a multimodal large language model (LLM). The AI agent trains itself to recognize 3D images of the workplace using information from written documentation (i.e., safety rules, etc). Context memory technology uses written information to selectively retain only the relevant data, enabling the analysis of long-duration video content with world-leading accuracy (1).
The AI agent will be evaluated by FieldWorkArena, an evaluation environment newly developed by Fujitsu, under the supervision of Carnegie Mellon University. FieldWorkArena will be made available for the researcher community from December 2024, with tasks being added to GitHub and the Fujitsu Research Portal in December 2024.
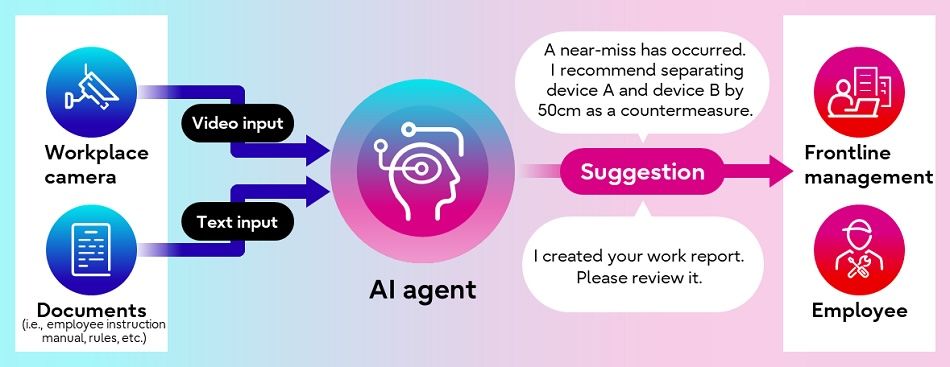
Figure 1: The video analytics AI agent for frontline workplaces
Training to operate in the frontline workplace based on written documentation
This technology augments the AI agent’s video data comprehension capabilities using information from written documentation to help the LLM understand what it cannot from video content alone. Figure 2 below shows how this technology can be applied to understand the spatial relationship between people and objects. In addition to spatial relationships, the technology will also help the AI agent to recognize workplace objects and individual tasks carried out by employees. Potential applications of this technology include assessing the distances between people and objects in logistics and construction sites, and automatically updating work-task status via production management systems to visualize production status in real time.
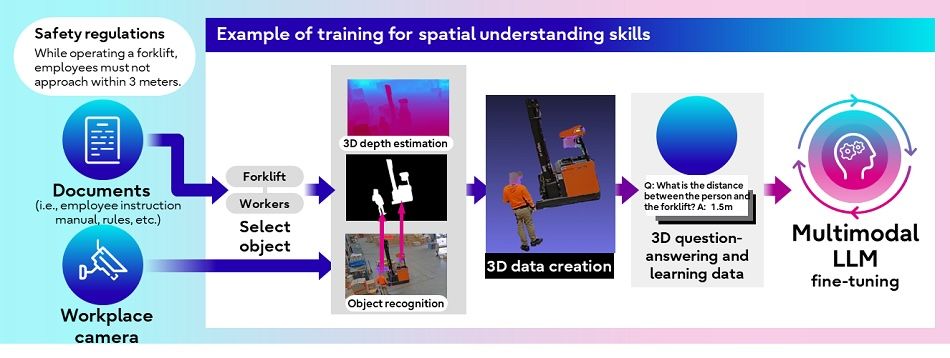
Figure 2: Training to operate in the frontline workplace
Efficiently retaining context data from video content
When large, long-duration video content is input into current multimodal LLMs, it suffers framerate drops which results in poor response accuracy. To solve this issue, Fujitsu focused on the selective attention mechanism found in humans, which efficiently processes visual information by focusing on the contextually important details. This technology allows for the user to provide a prompt for a specific type of behavior to focus on in a video, i.e., “safe behavior in humans.” The AI agent will then select only the specific frames and features that correspond to the prompt and compress and store them as video context data. Using this video context data, the multimodal LLM can process long-duration video content without the frame rate dropping. In a question-answering benchmark test carried out using long-duration video content including videos of more than 2 hours, Fujitsu achieved the world's highest answer accuracy with the smallest storage capacity as compared to conventional video compression technology for multimodal LLMs.
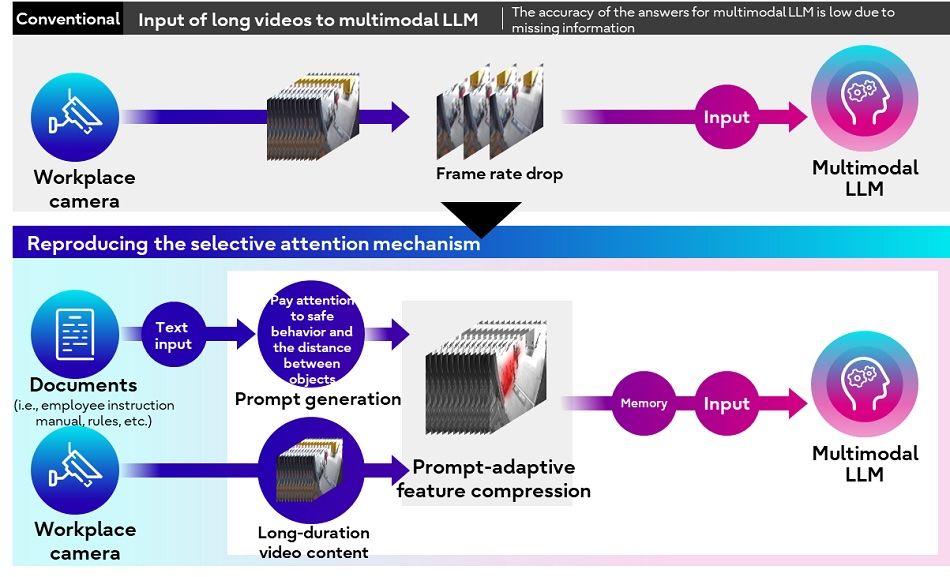
Figure 3: Retaining video context data through selective attention
FieldWorkArena
Under the supervision of Carnegie Mellon University's Associate Professor Graham Neubig and Assistant Professor Yonatan Bisk, Fujitsu has developed the FieldWorkArena, an evaluation environment for its video analytics AI agent service. The FieldWorkArena includes a bank of images and video content from actual frontline workplaces including plants and warehouses, documents such as rules and instruction manuals, simulations of business systems, and sets of tasks for the AI agent to solve (Figure 4). It will evaluate the performance of AI agents in actual operations.

Figure 4: Examples of data and tasks in the FieldWorkArena
(1)Benchmark carried out on December 12, 2024. Accuracy of responses to 599 question subsets (those that can be answered referring to video content alone) using the ultra-long video duration benchmark InfiniBench (average video length 49 minutes, maximum video length 151 minutes)
About Fujitsu
Fujitsu’s purpose is to make the world more sustainable by building trust in society through innovation. As the digital transformation partner of choice for customers in over 100 countries, our 124,000 employees work to resolve some of the greatest challenges facing humanity. Our range of services and solutions draw on five key technologies: Computing, Networks, AI, Data & Security, and Converging Technologies, which we bring together to deliver sustainability transformation. Fujitsu Limited (TSE:6702) reported consolidated revenues of 3.7 trillion yen (US$26 billion) for the fiscal year ended March 31, 2024 and remains the top digital services company in Japan by market share. Find out more: www.fujitsu.com.
Press Contacts
Fujitsu Limited
Public and Investor Relations Division
Inquiries
Copyright 2024 JCN Newswire. All rights reserved. www.jcnnewswire.com
© 2024 JCN Newswire. All rights reserved. A division of Japan Corporate News Network.